
De hiervoor beschreven OLTP relationele database een veel voorkomende is, zijn er vele anderen die u tegen kunt komen. Zelfs als er niet dagelijks et een van de andere gewerkt wordt, is het nuttig er toch kennis van op te doen. In deze les worden enkele van de andere vormen besproken en de belangrijkste kenmerken van elke.
Leerdoelen van deze les
Na het afronden van deze les ben je bekend met de kenmerken van:
- Datawarehouse
- Online Analytical Processing (OLAP) databases
- Hiërarchische databases
- Kolom georiënteerde databases
- NoSQL en Hadoop databases
Data Warehouse
In de voorgaande onderwerpen is de relationele database met OLTP beschreven. Met relationele databases kunnen ook Data Warehouses ontwikkeld worden. Een Data Warehouse is een erg grote database waarin meestal historische gegevens opgeslagen worden, in plaats van actuele gegevens. Een bedrijf heeft bijvoorbeeld een OLTP database voor de huidige maand en een Data Warehouse voor alle voorgaande maanden en jaren.
Met deze historische gegevens kunnen bedrijven onderzoeken hoe het presteert of plannen maken voor de toekomst. Een onderdeel hiervan kan zijn de verkoop prestaties over een langere periode en de invloed van verkoop campagnes, of om verkoop trends te voorspellen.
Dubbele gegevens en denormalisatie
Een relationeel Data Warehouse heeft, net als een OLTP database, gerelateerde tabellen. In een OLTP database streeft men ernaar om dubbele data te minimaliseren om de verwerkingssnelheid te optimaliseren. Het nadeel hiervan is dat bij het uitvragen van deze databases gerelateerde gegevens bij elkaar gezocht moeten worden. Dit kan in theorie veel tijd kosten. Omdat het voornaamste proces bijeen OLTP database het toevoegen van gegevens is en niet het uitvragen is dit meestal geen probleem.
Voor Data Warehouses geld dat het toevoegen meestal geen dagelijkse bezigheid is. Over het algemeen worden gegevens in grote hoeveelheden aan een Data Warehouse toegevoegd, bijvoorbeeld wekelijks of maandelijks. Tussen deze laad acties door worden gegevens uitgevraagd om te kunnen analyseren. Hierdoor wordt bij het ontwerp van een Data Warehouse gebaseerd op prestaties bij het uitlezen in plaats van toevoegen.
Er worden meerdere methoden onderkend bij het ontwerpen van Data Warehouses. Onder de meest voorkomende zijn Ralph Kimballs dimensioneel ontwerp en Bill Inmons genormaliseerd model. Bij het eerste wordt het Data Warehouse zo ontworpen zo dat het veel dubbele gegevens bevat. Dit ontwerpproces wordt denormalisatie genoemd.
Gegevens aan een Data Warehouse toevoegen
De gegevens voor een Data Warehouse kunnen uit veel verschillende bronnen komen waaronder spreadsheets en customer relationship management (CRM) systemen. Een veelgebruikte gegevensbron zijn de bedrijf eigen OLTP databases. Om gegevens vanuit een bron naar het Data Warehouse over te zetten wordt een Extract, Transform and Load (ETL) proces gebruikt.
Dit ETL proces voert de benodigde wijzigingen door in de gegevens om het geschikt te maken voor het Data Warehouse. Hieronder kan het verwijderen van overbodige gegevens van, het samenvoegen van gegevens uit meerdere kolommen naan een enkele, of het berekenen van totalen per order detail en een totaal generaal voor de gehele order.
Het ster schema
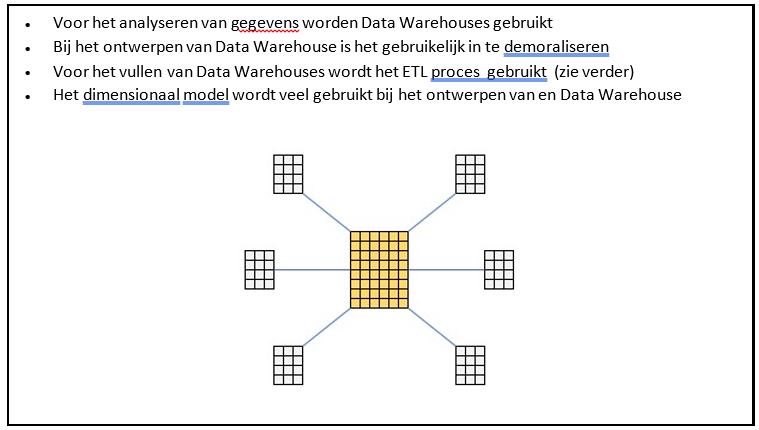
Er is meestal een grote tabel bij het ontwerpen van een relationeel Data Warehouse volgens het dimensioneel ontwerp. Deze tabel wordt de feiten tabel (fact table) genoemd. Hierin worden de belangrijkste numerieke waarden opgeslagen, zoals verkoopgegevens, kosten en dergelijke. Deze gegevens vormen de kern waarop analyses plaats vinden. Vaak zullen aggregaties plaatsvonden op basis van tijd, locatie of product soort.
De overige tabellen in het Data Warehouse bevatten omschrijvende informatie, deze tabellen worden dimensie tabellen genoemd. Voorbeelden hiervan zijn een producten tabel of een tabel met geografische informatie. Dit concept kan gezien worden als een ster. Met de feiten tabel in het midden en de dimensie tabellen eromheen. Zie het voorbeeld aan het begin van deze paragraaf.
Online Analytical Processing Databases
Een Data Warehouse dient vaak als gegevensbron voor een Online Analytical Processing (OLAP) systeem. Deze systemen gebruiken voor gedefinieerde gegevens en gespecialiseerde gegevensopslag voor snelle analyse van zeer grote hoeveelheden gegevens.
Multidimensionale databases
Het meest gebruikte OLAP systeem is gebaseerd op het Multidimensionale model.
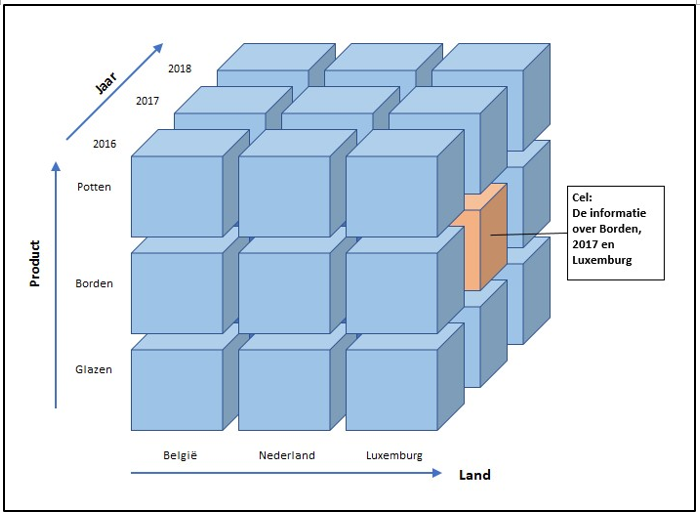
In een dergelijk model wordt een structuur ontwikkeld met de naam kubus (Cube), waarin de gegevens opgeslagen worden. De gegevens zijn discreet, geaggregeerd en numeriek, bijvoorbeeld verkoopresultaten of productiekosten. In de kubus zijn deze gegevens opgeslagen in cellen met onderscheidende kenmerken, zoals Land, Product of Jaar.
Elke cel is een positie in de kubus die gerepresenteerd wordt door de intersectie van de kenmerken. Als bijvoorbeeld behoefte is aan de geaggregeerde gegevens van verkochte borden in Luxemburg in het jaar 2017 is deze informatie snel te vinden.
Gegevens in een kubus zijn vooraf geaggregeerd, wat inhoudt dat bij het ophalen van de gegevens geen berekeningen meer hoeven plaats te vinden. Hierdoor is het minder belastend voor de systemen waarop het Data Warehouse is opgeslagen. Ook wordt het behandelen van het uitvragen sneller.
Voor het uitvragen van een kubus wordt de Multidimension Expression (MDX) taal gebruikt, alhoewel veel analisten programma’s als Excel gebruiken. Door een koppeling vanuit zo’n programma naar het Data Warehouse te leggen zal dat programma, namens de analist, de MDX uitvraging regelen.
| • | Opmerking: Kubussen in een multidimensionale database hebben bijna altijd meer kenmerken dan de drie zoals hier beschreven. Hierdoor is het driezijdige concept van een kubus niet altijd intuïtief. |
Multidimensionale gegevensopslag
Voor deze opslag zijn er drie opslag principes
- Multidimensional OLAP (MOLAP):
Bij MOLAP databases, wordt de kubus gecreëerd en vervolgens gevuld met gegevens en aggregatie. Dit vul proces kan een zware belasting zijn voor het systeem en langdurig afhankelijk van de hoeveelheid gegevens. Na het vullen zal een MOLAP zelfstandig kunnen werken totdat er nieuwe gegevens aan toegevoegd moeten worden. Op het moment dat er gegevens uitgevraagd moeten worden zijn deze gegevens compleet en direct beschikbaar waardoor dit het beste presteert. Een nadeel is dat de gegevens in een MOLAP over het algemeen verouderd zijn tussen twee laadprocessen. Om de gegevens in een MOLAP actueel te krijgen moet een laadproces uitgevoerd worden. - Relational OLAP (ROLAP):
ROLAP opslag gebruikt de oorspronkelijke relationele database, wat een data warehouse kan zijn) om de cel gegevens op te slaan, in plaats van de gegevens te verwerken en in een kubus op te slaan. Bij het uitvragen wordt ook de eerder besproken MDX gebruikt, maar de OLAP server bevraagd op zijn beurt de relationele database. Dit is minder efficiënt en kost meer tijd in vergelijking met MOLAP. ROLAP heeft twee voordelen:- De gegevens die de gebruiker te zien krijgt zijn actueel als de ROLAP de relationele database gebruikt. Als een Data Warehouse gebruikt wordt is de actualiteit afhankelijk van de frequentie waarmee deze aangevuld wordt.
- De benodigde opslagcapaciteit in beduidend minde als voor een MOLAP omdat de gegevens opgeslagen worden op één plek in plaats van twee zoals bij een MOLAP.
- Tabular Data Models:
Tabular Data Models zijn een onderdeel van Microsoft SQL Server Analysis Services. Dit model is een alternatieve benadering om een analytische oplossing te creëren, waarin de gegevens gepresenteerd worden in een relationeel formaat. Dit is eenvoudiger om te begrijpen en om mee t e werken dan het multidimensionale model, maar heeft niet alle mogelijkheden van de laatste.
Meer informatie over de verschillen tussen tabular en multidimensionale datamodellen klik op link:
Comparing Tabular and Multidimensional Solutions (SSAS).
Hierarchical Databases
Hoewel relationele databases de meest gebruikte type databases zijn, zijn er verschillende andere typen die je kan tegen komen zoals hiërarchische of NoSQL databases
Opbouw van hiërarchische databases
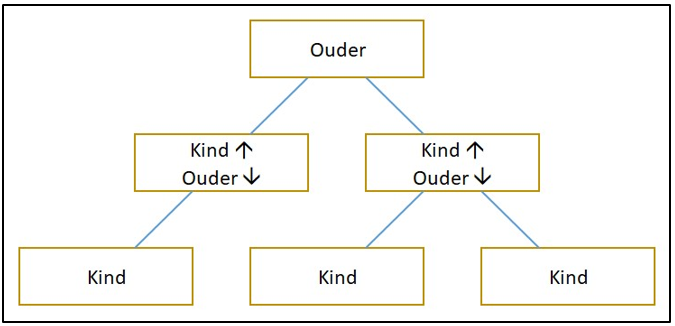
In hiërarchische databases worden de gegevens op een anders georganiseerd als in een relationele database. In plaats van het arrangeren van de gegevens via relaties worden de gegevens als een hiërarchie gearrangeerd. Een hiërarchie is een structuur over meerdere lagen waarbij een onderdeel in elke hogere laag de ouder is van alle onderdelen in de laag er direct onder. Deze onderdelen worden kinderen genoemd.
De hiërarchische structuur is te vergelijken met een omgekeerde boom. Met de stam als de eerste ouder en de takken als alle kinderen en ouders van elke volgende laag. In een hiërarchische database heeft elk kind één ouder, maar elke ouder kan vele kinderen hebben. Oftewel: er is een one-to-many relatie tussen een ouder en de kinderen. Bij het uitlezen van gegevens uit een hiërarchische database, wordt bij de eerste ouder begonnen, om vervolgens langs de kind-ouder punten te gaan tot de gewenste gegevens gevonden zijn. De niveaus in een hiërarchie zijn gekoppeld met verwijzingen, waardoor vanuit een knoppunt naar het volgende gegaan kan worden.
Sommige gegevens zijn van nature hiërarchisch en daardoor geschikt voor opslag in een hiërarchisch systeem. Bijvoorbeeld het arrangeren van mappen, sub-mappen en bestanden in een bestandssysteem zijn voorbeelden van een natuurlijke hiërarchie. Elk bestand (kind) kan slechts voorkomen in één map (ouder), maar in mappen kunnen meerdere bestanden opgeslagen worden. En in een map kan weer een sub-map komen. Het door Windows gebruikte bestandssysteem is een voorbeeld van dit type hiërarchische database.
Beperkingen van een hiërarchische database
Hiërarchische databases kunnen zeer goed overweg met one-to-many relaties, maar zijn niet geschikt voor many-to-many relaties. Een verkoop administratie is een voorbeeld van een many-to-many relatie.
Ieder product kan in meerdere orders voorkomen en in iedere order kunnen meerdere producten voorkomen. Omdat dit geen eenvoudige one-to-many relatie is, is het moeilijk dit in een hiërarchische database vast te leggen. Het is veel eenvoudiger dit vast te leggen in een relationele database.
| • | Opmerking: Het hiërarchische datamodel is in de zestiger jaren door IBM ontwikkeld. Het relationele datamodel, eerder besproken in deze cursus, is later ontwikkeld. Een van de redenen om het relationele model te ontwikkelen waren vanwege de beperkingen van het hiërarchische model. |
Sommige versies van relationele databases bieden de mogelijkheid om gegevens in een hiërarchische manier op slaan. SQL Server bijvoorbeeld heeft het “hierarchyid” data type beschikbaar.
Kolom georiënteerde databases
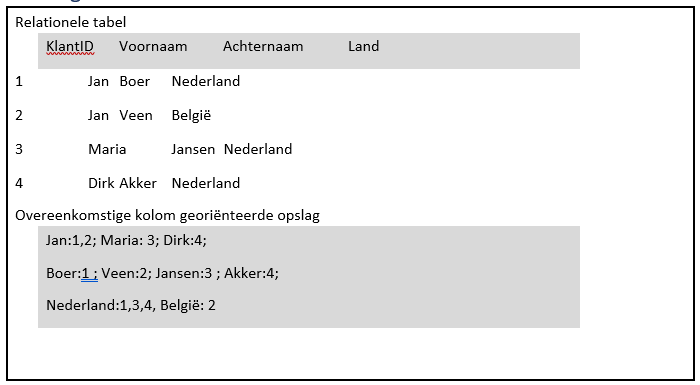
De naam kolom georiënteerd refereert aan een methode om data op te slaan zodat in specifieke gevallen de gegevens snel uitgevraagd kunnen worden. In tegenstelling tot een relationele database waarbij de gegevens in rijen opgeslagen worden, worden de gegevens in een kolom georiënteerde database per kolom in een enkel regel opgeslagen. Hierboven staat een voorbeeld hiervan.
Zoals te zien is, worden de gegevens opgeslagen met het bijbehorende KlantID. In de eerste regel staan alleen de voornamen, in de tweede regel staan de achternamen en de derde regel het land. Het is duidelijk te zien dat de voornaam “Jan” twee keer voorkomt en “Nederland” drie keer.
Het op deze wijze arrangeren van de gegevens maakt het in sommige gevallen sneller en efficiënter bij het uitvragen, omdat het aantal keer dat het DBMS de schijven waarop de gegevens staan moet benaderen. Het benaderen van schijven, wat schijf input – output (IO) genoemd wordt, is een van de knelpunten van een databasesysteem. Door dit te verminderen wordt de prestatie van de uitvraging verbeterd. Echter is de verbetering van de prestaties bij kolom georiënteerde opslag zeer specifiek en gelimiteerd. Uitvragingen waarbij gegevens geaggregeerd worden van een relatief beperkt aantal gegevens uit de totale gegevens set kunnen in een kolom georiënteerde database beter presteren. Maar hier is geen garantie voor af te geven en het vereist een nauwkeurige ontwerp en plan.
Hoewel SQL Server een relationeel DBMS is, bied het de mogelijkheid voor kolom georiënteerde opslag waarvoor het de Columnstore index heeft. Voor het optimaliseren van de prestaties bij grote datatabellen wordt in geheugen technologie gebruikt inclusief compressie.
NoSQL

NoSQL wordt gebruikt om te refereren aan allerhande types van gegevensopslag die een ding gemeen hebben: ze zijn niet gebaseerd op het relationele model. NoSQL databases worden de laatste jaren steeds belangrijker door bijvoorbeeld:
- De toenemende hoeveelheid Big Data. Dit is een paraplu naam waaronder allerhande gegevens vallen zoals documenten, video’s, foto’s, geluidsbestanden en email. Dit zijn ongestructureerde gegevenstypen, althans zonder structuren die vergelijkbaar zijn met een relationele database. Gestructureerde gegevens zijn dusdanig georganiseerd dat de semantische betekenis behouden blijft. Van een kolom met als naam postcode in een tabel met klantgegevens is duidelijk waar het om gaat. Bij relationele databases wordt tijdens het ontwerpen bepaald welke soort gegevens in elke kolom kunnen komen. Dit wordt Strong Typed genoemd. Big Data daarnaast kan door het type gegevens enige structuur hebben, zoals bij XML. Maar vele andere gegevens missen elke structuur zoals bij documenten of video’s. NoSQL databases kunnen hier meestal uitstekend mee omgaan.
- Organisaties kunnen gebruik maken van beschikbare hardware, virtualisatie en clouddiensten.
Hierdoor is het eenvoudiger en goedkoper geworden om “schaalbare” oplossingen in te zetten. Hierbij wordt naar behoefte de verwerking over meerdere, al dan niet virtuele) servers verdeeld om de rekenkracht te vergroten. Bij “schaalvergroting” wordt de gebruikte server intern opgewaardeerd met meer geheugen of processoren. Door de praktisch onbegrensde mogelijkheden van schaalbare oplossingen kunnen deze op grote schaal rekenkracht leveren.
Hierdoor zijn diverse technieken ontstaan waarbij de kracht van schaalbaar gebruikt wordt voor het opslaan en bewerken van de hier besproken bestandstypen. Deze technieken maken geen gebruik van relationele datamodellen, daarom vallen ze onder de noemer NoSQL. Enkele van deze technieken zijn ontstaan voordat de term NoSQL werd bedacht.
Beperkingen van NoSQL databases
NoSQL databases zijn uitermate geschikt voor het werken met grote gegevenssets en de prestaties die daarmee bereikt worden. Een belangrijke beperking is dat ze vaak niet een belangrijk deel van de relationele database functionaliteit bieden. Relationele databases beveiligen transacties met een serie criteria waarvoor het acroniem ACID gebuikt wordt:
A – Atomicity
Elke verwerking moet compleet verwerkt kunnen worden. Als tijdens de verwerking een stap mislukt, wordt de status van de database teruggebracht naar de situatie voorafgaand aan de gehele verwerking
C – Consistency
Elke wijziging laat een database achter die volledig aan het ontwerp voldoet
I – Isolation Elke verwerking wordt uitgevoerd zonder invloed uit te oefenen op andere verwerking of zich laten beïnvloeden door andere verwerkingen
D – Durability
Volledig uitgevoerde verwerkingen zijn na voltooiing definitief
| • | Opmerking: Sommige NoSQL databases bieden het gebruik van uitvraag talen, vergelijkbaar met SQL, die de naam “Not Only SQL” hebben gekregen, als alternatief voor NoSQL |
NoSQL database types
Er is niet een enkele NoSQL database, hieronder een tweetal voorbeelden ervan.
- Document georiënteerde databases:
Zoals de naam al weergeeft, in dit type database kunnen semigestructureerde documenten bewaard worden. Voorbeelden hiervan zijn XML (Extended Markup Language) en JSON (JavaScript Object Notation) documenten. Deze zijn semigestructureerd omdat ze metadata bevatten (zoals de tags in XML), waar mee de betekenis van de gegevens aangegeven wordt. Elk document kan echter compleet verschillende metadata bevatten wat in een relationele database niet mogelijk is omdat elke rij dezelfde soort inhoud moet hebben. Documenten worden in combinatie met een unieke sleutel opgeslagen, waardoor ze terug te vinden zijn. - Object georiënteerde databases: Met een object georiënteerde programmeertaal, zoals C#, Java, Perl of Visual Basic, zijn object georiënteerde database te maken. Als de gegevens die opgeslagen moeten worden complex zijn kan dit type database een oplossing bieden, denk hierbij aan onder andere computer aided design (CAD). In dit type database worden de gegevens als complete objecten opgeslagen, bij klantgegevens zal het kunnen gaan om bijvoorbeeld attributen: naam, adres en telefoonnummer. Maar naast attributen hebben objecten ook methoden voor bijwerken of verwijderen. De structuur van een klantobject, met attributen en methoden wordt gedefinieerd als klasse. Vanuit een klasse wordt een nieuw object gecreëerd.
Hadoop
| • | Hadoop is een big datatechniek waarmee met veel verwerkingskracht erg grote hoeveelheden gegevens geladen kunnen worden |
| • | In SQL Server 2016 is PolyBase opgenomen, dit integreert SQL Server met Hadoop omgevingen |
Net als de hierboven beschreven NoSQL databases is Hadoop een schaalbare omgeving voor het opslaan van en werken met semi- en ongestructureerde gegevens. Hadoop bestaat uit een groep aan elkaar gerelateerde technieken waaronder:
- Het Hadoop Distributed File System (HDFS). Hadoop slaat gegevens op verdeeld over meerdere computers, waarbij grote bestanden in stukken verdeeld worden over de beschikbare computers.
- Hadoop MapReduce is een programma dat gebruikt kan worden om de verwerking over meerdere computers te verdelen, wat snellere prestaties oplevert.
Hoewel Hadoop en NoSQL databases allebei big data kunnen verwerken zijn er wel verschillen. Hadoop is ontworpen voor verwerking in grote hoeveelheden en presteert zeer goed met alleen lezen acties. NoSQL daarentegen presteert het beste met lees en schrijf acties met grote hoeveelheid gegevens, zoals bij web applicaties.
Hadoop en SQL Server
In SQL Server is de technologie PolyBase opgenomen waarmee Hadoop databases uitgevraagd kunnen worden. Met PolyBase kun je:
- Gegevens ophalen uit Hadoop of Azure Blob Storage door gebruik te maken van Transact SQL.
- Gegevens van SQL Server opslaan in Hadoop of Azure Blob Storage.
- Met de Microsoft Business Intelligence (BI) tools gegevens analyseren en rapporten maken gebaseerd op Hadoop gegevens.
Voor meer informatie over PolyBase ga naar de informatie op de Microsoftsite: PolyBase Guide: http://aka.ms/Aqamxl
SQL GRAPH

SQL Graph in nieuw in SQL Server 2017. Met een Graph database kunnen complexe relaties gemodelleerd worden, en eenvoudiger analyseren van many-to-many relaties.
SQL Graph maakt het mogelijk om complexe relaties structuren op te slaan en te bevragen. Het bied geen extra functies zoals bij een relationeel datamodel.
Wat is SQL Graph
Een Graph database bestaat uit twee elementtypen: een NODE (knooppunt) en een EDGE (relatie). Voor elk van deze twee wordt in SQL Server een aparte tabel gecreëerd. Hiervoor zijn in SQL Server 2017 de sleutelwoorden AS NODE en AS EDGE aanwezig.
Wanneer wordt SQL Graph gebruiken
Graph databases zijn in het bijzonder geschikt als
- Er zijn hiërarchische gegevens aanwezig waarbij entiteiten een of meer ouders hebben
- De gegevens hebben complexe many-to-many relaties
- De gegevens moeten geanalyseerd worden en uitgevraagd hoe de relaties liggen
Graph data uitvragen
Met het nieuwe sleutelwoord MATCH wordt het mogelijk de Graph database te bevragen. Dit nieuwe sleutelwoord moet gebruikt worden in het WEHRE gedeelte van een SELECT commando.