
Onder de term database vallen verschillende typen van dataopslag, elk met hun eigen specifieke mogelijkheden. In deze les wordt beschreven wat een database is en wordt de relationele database voorgesteld. Dit is de meest voorkomende database vorm.
Leerdoelen van deze les
Na afronding van deze les, ben je bekend met:
- Wat een database is
- De belangrijkste kenmerken van een relationele database
- Relaties in een data
- Het concept van normaliseren
Wat is een database eigenlijk?
Een database is een georganiseerde opslagmethode voor gegevens zodat deze snel terug gevonden kunnen worden. Meestal worden gegevens op een manier opgeslagen zodat meervoudige opslag van hetzelfde voorkomen wordt, wat zorgt voor:
- Efficiëntere opslag van de gegevens
- Vermindering van gegevensfouten
Uitvraagtalen bieden de mogelijkheid om op een standaard manier de gegevens in de database uit te vragen of wijzigen.
Een Database-Management System (DBMS) is een softwarepakket waarmee databases gemaakt en onderhouden kunnen worden.
Eenvoudigweg is een database gewoon een georganiseerde opslagmethode voor gegevens. Door het organiseren van gegevens op een logische en consequente manier wordt het mogelijk het sneller en eenvoudiger te benaderen als je de gegevens nodig hebt. Als boeken gesorteerd op onderwerp, titel en/of schrijver zijn, kan je sneller een specifiek boek vinden. Deze principes van organiseren in een database maken het terugzoeken efficiënter. Maar er is geen eenduidige correcte manier waarop gegevens in een database georganiseerd moeten worden. Om het lastiger te maken zijn er meerdere verschillende types database tegenwoordig in gebruik
De meest bekendedatabase is de relationele database. Deze bestaat uit meerdere tabellen elk met regels gegevens verdeeld over meerdere kolommen. Dit is vergelijkbaar met een spreadsheet. De tabellen in dit type database hebben relaties. Bijvoorbeeld heeft een tabel met persoonsgegevens een relatie met een tabel met universele landgegevens. Hierdoor hoeft bij elk persoon alleen een landcode vastgelegd te worden. Door de relatie zijn de algemene land gegevens aan elk persoon gerelateerd. In hierop volgende lessen wordt dit nader uitgelegd. Andere veel voorkomende database types zijn:
- Hiërarchische databases
- Object georiënteerde databases
- Kolom georiënteerde databases
Meervoudige opslag
Als toevoeging op het sneller en eenvoudiger terugvinden van gegevens wordt de opslag efficiënter door meervoudige opslag te verminderen. Meervoudige opslag betekend dat exacte dezelfde gegevens meerdere keren opgeslagen worden. Als het hiervoor beschreven voorbeeld met persoonsgegevens kunnen de universele land informatie bij elk persoon opgeslagen worden. Bij een lange lijst met personen wordt telkens bijvoorbeeld landnaam, landcode, land telefoonnummer herhaald. Dit heef als resultaat dat er meer opslagruimte nodig wordt als de persoonslijst langer wordt.
Daarnaast neemt door meervoudige opslag de kans afwijkingen toe door typefouten. Bijvoorbeeld Belgie bij een persoon en België bij een volgende. Welke van deze twee zal gebruikt worden als alle personen uit België uit de database geselecteerd moeten worden?
Het is belangrijk dat gegevens eenduidig zijn, omdat dit van invloed is op de resultaten bij uitvragen van gegevens. Voor het maken van bedrijfsbeslissingen zijn accurate resultaten van uitvragingen erg van belang. Door verschillende type gegevens in verschillenden tabellen vast te leggen wordt meervoudige opslag verminderd. Dus de algemene landgegevens kunnen opgeslagen worden in een eigen landen tabel.
Gegevens in databases benaderen
Om de gegevens in een data te kunnen benaderen, moet je de database kunnen uitvragen. Dit gebeurt meestal met een speciaal programma. Er zijn meerdere talen waarmee een database uitgevraagd kan worden. Deze talen zijn afhankelijk van het type database dat benaderd wordt. De meest bekende taal voor relationele databases is: Structured Query Language (SQL). Andere mogelijke talen zijn XQuery en Multidimensional Expressions.
Data managementsystemen
Een database managementsysteem (DBMS) is het programma dat op een server geïnstalleerd moet worden om databases te maken en onderhouden. Een enkel DBMS kan meestal meerdere databases ondersteunen. Algemeen bekende DBMSen zijn Microsoft SQL Server, MySQL en Oracle. De meeste DBMSen beiden uitgebreide administratieve mogelijkheden zoals het maken van een back-up en de algemene staat van de database te controleren. Een DBMS ondersteund ook toegangs- en gebruiksrechten en versleuteling.
Basiskennis Relationele Databases
Eind zestiger jaren is door Edgar F. Codd een efficiënte maniervan gegevensopslag voorgesteld.
Relationele databases zijn gebaseerd op dit theoretische model.
Dit is vrijwel zeker de meest bekende
en toegepaste type database over de hele wereld. Voorbeelden van relationele DBMSen zijn SQL Server, Sybase en Oracle.
Tabellen, rijen en kolommen
In relationele databases worden de gegevens opgeslagen in tabellen. Een enkele database omvat meestal meerdere tabellen. Elke tabel bevat een specifiek deel van de gegevens binnen de database. Bijvoorbeeld de database voor verkoopgegevens heeft tabellen voor: Klanten, Producten,
Verkooporders, Orderregels en Vervoerders.
Elk van deze tabellen bevat allen gegevens waarvoor de tabel bedoeld is.
In elke tabel worden de gegevens opgeslagen in regels. Elke regel bevat de complete set van de voor de tabel geldende gegevens. Deze gegevens worden vastgelegd in kolommen, bijvoorbeeld bij klantgegevens: voornaam, achternaam, adres en telefoonnummer. Per regel heeft elke kolom een enkele waarde.
In sommige boeken over relationele databases worden soms andere worden gebruikt, bijvoorbeeld “relation”, “tuple” en “attribute”. Deze komen voort uit het oorspronkelijke voorstel van Codd, en zijn meer gericht op het door hen beschreven concept dan de eigenlijk toepassing ervan.
In module 2 wordt hierop dieper ingegaan. De meeste van de huidige DBMSen gebruiken de termen tabel (table), rij (row) en kolom (column) voor respectievelijk relation, tuple en attribute. Het is verstandig deze oude termen te onthouden omdat de kans bestaat dat ze in andere boeken gebruikt worden. Andere gebruikte termen zijn “record” voor “rij” en “field” voor “kolom”.
Gegarandeerde uniekheid door primaire sleutels te gebruiken
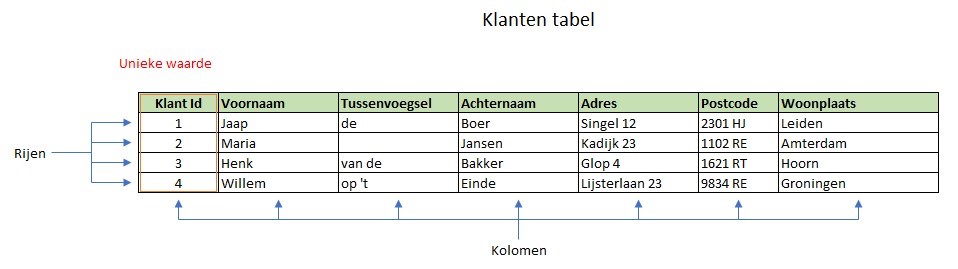
Een tabel zal in veel gevallen een kolom hebben, waarin een unieke waarde vastgelegd wordt. Dit maakt het mogelijk om eenduidig de regel te identificeren. Deze unieke waarde kan ook buiten de database een betekenis hebben, zoals een artikel nummer in een producten tabel. Het kan ook een waarde hebben die alleen binnen de database een betekenis heeft. Een klanten tabel kan een kolom met de naam KlantID hebben waarin een oplopend nummer wordt vastgelegd.
Klant IDNaamTussenvoegselAchternaam
1 JaapdeBier2 Maria
Jansen3 Willemop ’tEinde
Buiten de database heeft het KlantID geen betekenis, het identificeert alleen de klant binnen de database. Het is belangrijk om ervoor te zorgen dat er een waarde slechts één keer voorkomt in deze kolom. Als er bijvoorbeeld 2 regel zijn met hetzelfde KlantID zijn deze twee regels niet van elkaar te onderscheiden.
Stel je voor dat je een rapport wil maken van alle klanten met hun orders. Als twee klanten hetzelfde KlantID hebben zullen de alle orders van beide klanten twee keer op het rapport verschijnen. Om dit te voorkomen wordt in het tabel ontwerp een primaire sleutel beperking (primary key constraint) op deze kolom toegevoegd.
Een beperking (constraint) beperkt je in de mogelijkheden bij toevoegen aan of wijzigen in een tabel. Er kunnen verschillende beperkingen ter tabel opgelegd worden om inconsequenties te voorkomen. Het
definiëren van een unieke sleutel beperking op een kolom, voorkomt
het invoeren van dubbele waarden in deze kolom, zodat elke waarde uniek is.
Tabellen in Relationele Databases
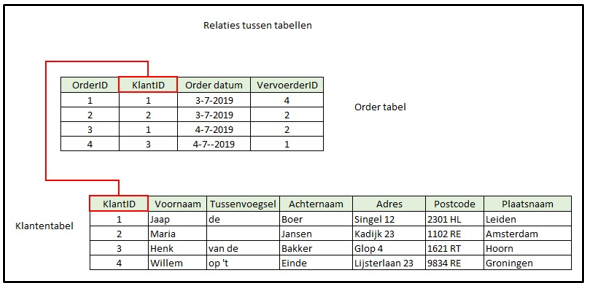
Tabellen in een relationele database zijn aan elkaar gerelateerd. Deze relatie is te beschrijven zoals in het echte proces waarop de database gemodelleerd wordt. Klanten plaatsen bijvoorbeeld orders voor meerdere producten. De database waarin deze transacties vastgelegd worden, zal tabellen bevatten voor elk van deze gegevens: Een Klanten tabel voor de klantgegevens, een Order tabel voor elke order gegevens, een Producten tabel voor de productgegevens en een Orderdetail tabel voor de uiteindelijk producten in de bestelling.
Als aanvulling, als het bedrijf de bezorging door een externe partij gebruikt, kan een Vervoerders tabel opgenomen worden waarin de gegevens per vervoerder vastgelegd worden. De Order tabel zal geen uitgebreide gegevens van de klanten bevatten, deze staan in de Klantentabel. In plaats daarvan zal de Ordertabel een kolom bevatten met als naam KlantID. Hierin komt een waarde waarmee de bestellende klant geïdentificeerd kan worden. Elke waarde die hierin vastgelegd wordt moet voorkomen als unieke waarde in de klantentabel. In onderstaand voorbeeld wordt dit getoond:
Klantentabel
| KlantID | Voornaam | Tussenvoegsel | Achternaam | Adres | Postcode | Plaatsnaam |
| 1 | Jaap | de | Boer | Singel 12 | 2301 HL | Leiden |
| 2 | Maria | Jansen | Kadijk 23 | 1102 RE | Amsterdam | |
| 3 | Henk | van de | Bakker | Glop 4 | 1623RT | Hoorn |
| 4 | Willem | op ‘t | Einde | Lijsterlaan 23 | 9834 RE | Groningen |
Ordertabel
| Order ID | KlantID | Order datum | VervoerderID |
| 1 | 1 | 3-7-2019 | 4 |
| 2 | 2 | 3-7-2019 | 2 |
| 3 | 1 | 4-7-2019 | 2 |
| 4 | 3 | 4-7-2019 | 1 |
Deze werkwijze helpt met het voorkomen van meervoudige registraties om dat de klantgegevens alleen in de klanttabel staan en niet volledig herhaald worden bij elke order. Als een klant een order plaatst, wordt een regel toegevoegd in de order tabel, inclusief het KlantID waaronder de klant is opgenomen in de Klantentabel.
Verwijzende sleutels (Foreign Keys)
Als in de Ordertabel een regel staat waarvan het KlantID niet in de Klantentabel voorkomt, is de order niet uit te voeren omdat benodigde klantgegevens niet gevonden kunnen worden. Om dit te voorkomen kan een andere beperking op een tabel gedefinieerd worden: Verwijzende sleutel beperking (Foreign key constraint).
Als een verwijzende sleutel beperking voor een kolom wordt gedefinieerd, zal bij het toevoegen van regel gecontroleerd worden of de nieuwe waarde in deze kolom bekend is in een tweede kolom, de gerefereerde kolom. In dit voorbeeld zou een verwijzende sleutel beperking op het KlantID in de order tabel gedefinieerd worden, die refereert aan het KlantID in de Klantentabel. Hiermee wordt voorkomen dat er regels in de Ordertabel komen waarvan het KlantID onbekend is in de Klantentabel.
In tegenstelling tot primaire sleutel beperking geldt voor de verwijzende beperking dat deze niet uniek hoeft te zijn. Het is onlogisch om vast te leggen dan een KlantID maar één keer in de Ordertabel, dan zou elke klant maar één order kunnen plaatsen. De relatie tussen een primaire en verwijzende sleutel wordt een een-naar-meer (one-to-many) relatie genoemd. Dit bekend dat de verwijzende sleutel meerdere keren in de tabel voor kan komen, naar de sleutel waarnaar verwezen wordt slechts één keer. Dit is meesten de primaire sleutel in de andere tabel.
Om het voorbeeld van deze les compleet te maken, moeten primaire sleutel beperkingen vastgelegd worden voor de OrderId kolom in de Ordertabel, en voor de kolommen die uniek zijn in de overige tabellen. Afsluitend zal je verwijzende sleutel beperkingen vastleggen in de diverse tabellen, voor zover nodig.
Demonstratie: Een relationele database verkennen
In deze demonstratie wordt getoond:
- Het maken van een database diagram
- Het database diagram gebruiken om te kijken naar:
- Tabellen
- Primaire sleutel beperkingen
- Verwijzende sleutel beperkingen
Demonstratie stappen:
Normalisatie introductie
De eenvoudige order afhandeling database zoals hiervoor beschreven is een voorbeeld van een Online Transactional Processing (OLTP) database.
In OLTP databases, zoals deze, kun je veel toevoegingen verwachten, zoals het plaatsen van orders door de klanten. Daarnaast kunnen wijzigingen verwacht worden omdat klanten hun gegevens wijzigen. Denk hierbij aan bijvoorbeeld aan een contactpersoon.
Door bij het ontwerpen van de database rekening te houden met het minimaliseren van overbodige gegevens, gebeurt het toevoegen van regels zo snel als mogelijk. Als bijvoorbeeld een klant een order plaatst, zullen alleen de tabellen met order informatie gebruikt worden, en de overige niet. Bovendien zal deze toevoeg actie geen overbodige gegevens aanmaken, omdat de overige gegevens al bekend zijn in de database.
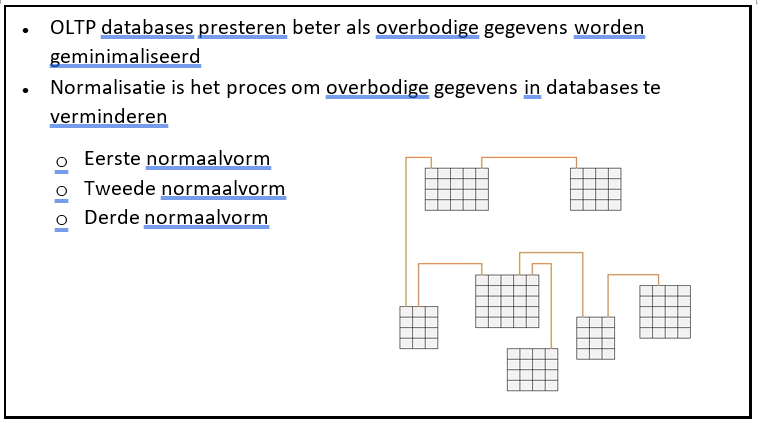
Normalisatie en de vormen
Het proces om overbodige gegevens is relationele databases te verminderen wordt normalisatie genoemd. Bij het ontwerpen van een database zal vaak een plan of schema gebruikt worden. Dit is een formeel proces waarbij meerdere stappen genomen worden.
Deze stappen heten eerste normaalvorm, tweede normaalvorm, derde normaalvorm en zo voort. In elke stap worden specifieke overbodigheidskwestie aangepakt. Elke volgende stap borduurt voort op de voorgaande. Om de tweede stap uit te kunnen voeren moet de eerste genomen zijn.
- De eerste normaalvorm behandeld het scheiden van gerelateerde gegevens over tabellen en zorgen ervoor dat elke tabel een uniek kenmerk (primaire sleutel) heeft. Aanvullen wordt het uitbannen van meerdere kolommen voor dezelfde soort gegevens. Denk hierbij aan twee telefoonnummers bij de klantgegevens.
- De tweede normaalvorm houdt in dat aan de eerste normaalvorm voldaan wordt. En alle gegevens in een tabel hebben alleen een betekenis in relatie met de sleutel in de tabel of zijn gerelateerd aan een andere tabel. Bijvoorbeeld de klantgegevens volledig gescheiden van de ordergegevens.
- De derde normaalvorm houdt in dat aan de tweede normaal vorm voldaan wordt. En de tabel bevat geen gegevens die bepaald kunnen worden uit onderliggende tabellen. Denk hierbij aan een ordertotaal dat berekend kan worden uit de order detail gegevens.
Er zijn nog meer normalisatie vormen. In module 3 van deze cursus komen deze aan de orde.
Weet je dit:
Welke van deze omschrijft het gebruik van een verwijzende sleutel?
⃝ Zorgen dat alle waarden in de kolom uniek zijn
⃝ Het voorkomen van overbodige gegevens
⃝ Om te controleren dat toegevoegde waarden correct zijn, door deze te refereren aan een andere kolom, meestal in een andere tabel.